
ApSIC Xbench es una de las mejores herramientas de control de calidad para traductores. Garantiza la coherencia de nuestros textos, ayuda a seguir los glosarios y otros materiales de referencia, y reduce los despistes al mínimo. También permite crear nuestras propias comprobaciones, que alcanzan todo su potencial cuando usamos expresiones regulares y las almacenamos en listas de comprobaciones. Por ejemplo, podemos codificar la guía de estilo de nuestro cliente de modo que Xbench nos indique las partes del texto que no la cumplen con tan solo pulsar un botón.
Xbench tiene dos versiones principales: la 2.9, que es gratuita, y la 3.0. Ambas se pueden descargar en la página oficial de Xbench. A pesar de que su sistema de cesión de licencias es extremadamente flexible y fácil de usar, no es difícil imaginar situaciones en las que unos miembros del equipo usan la versión de pago mientras otros prefieren la gratuita. También puede ser que un traductor empiece a utilizar la versión gratuita antes de decidirse a comprar la 3.0. En cualquier caso, suelen surgir dudas sobre la reutilización de recursos entre una versión y otra.
¿Puede usarse una misma lista de comprobaciones en 2.9 y 3.0?
Cualquier lista de comprobaciones puede importarse en cualquier versión de Xbench. Sin embargo, al cambiar de versión algunas de esas comprobaciones podrían no funcionar como se espera. Estas diferencias entre versiones pueden provenir de tres fuentes:
- Cambios en la sintaxis de las expresiones regulares.
- Corrección de errores.
- Incorporación de nuevas funciones.
Cambios en la sintaxis de las expresiones regulares
Una misma expresión puede dar resultados distintos en versiones distintas:
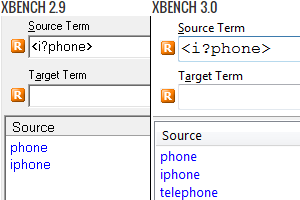
Este cambio se introdujo en la versión 1216 de Xbench 3.0. Antes de esta versión, la sintaxis de 2.9 y 3.0 era la misma. Afortunadamente, son solo cuatro los operadores cuyo comportamiento varía:
<: Inicio de palabra
>: Final de palabra
^: Inicio de segmento
$: Final de segmento
Además, esta diferencia solo sucede cuando están seguidos o precedidos de una expresión que puede estar vacía. Es decir, cuando los combinamos con estos otros operadores:
?: El carácter anterior es opcional
*: Cero o más repeticiones
Esta situación es la que ocurre en el ejemplo anterior. En principio, la expresión <i?phone> solo debería encontrar phone y iphone. Sin embargo, en 3.0 vemos que también ha encontrado telephone debido a que tras el cambio en cuestión el operador de inicio de palabra (<) solo interviene si existe esa i. Para lograr el resultado deseado habría que introducir agrupamientos con paréntesis, de modo que el operador < no pueda a afectar a una expresión vacía:
<(i?p)hone>
<(i?ph)one>
<(i?phone)>
Etc.
Estos paréntesis se consideran innecesarios en todas las sintaxis de las expresiones regulares habituales. Quizá por este motivo, poco después anularon este cambio, pero parece que solo a medias: se revirtió con los operadores de final de palabra o de segmento, pero no con los de inicio. La tabla siguiente ilustra esta incoherencia y cómo cambia la sintaxis de estos operadores entre versiones. Las celdas en verde indican coincidencia con la versión 2.9 y los números se refieren a la versión de Xbench 3.0, no a la evolución de las expresiones regulares en la Edad Media:
| Búsqueda | Hasta 1186 | 1216-1243 | Desde 1266 |
|---|---|---|---|
| phone o iphone | <i?phone> | <(i?phone)> | <(i?phone)> |
| phone o phones | <phones?> | <(phones?)> | <phones?> |
Corrección de errores y nuevas funciones
Otras dos posibles fuentes de diferencias entre versiones son la corrección de errores y la incorporación de nuevas funciones. Algunas de estas correcciones afectan al comportamiento de las expresiones regulares, por lo que hay tenerlas en cuenta al cambiar de una versión a otra. Por ejemplo, hasta la versión 1336 de Xbench 3.0 había que proteger con el carácter de escape todos los guiones para que no se interpretaran como un operador de intervalo. En el resumen final más abajo hay un ejemplo de este caso (es el ejemplo de Super-8) y otros parecidos.
En cuanto a las nuevas funciones, hay que tener especial cuidado cuando se utilice la normalización de caracteres. Un ejemplo práctico sería buscar vídeo. Con la normalización de caracteres activada, nos encontraría tanto vídeo como video. En las versiones que no tienen esta opción, solo nos encontraría vídeo. Afortunadamente, hay varias alternativas que funcionarían bien en todas las versiones, como las siguientes:
v[ií]deo
v(i|í)deo
video|vídeoResumen
Los archivos de listas de comprobaciones .xbckl pueden cargarse sin problema en cualquier versión de Xbench independientemente de la versión en la que se crearon. Sin embargo, muchas comprobaciones pueden perder su eficacia parcial o completamente si no se adaptan para cada versión, especialmente cuando se utilizan expresiones regulares.
Estos son algunos trucos para mejorar la compatibilidad de tus expresiones regulares entre versiones:
- Si los operadores de inicio de segmento o palabra van seguidos de una expresión que puede estar vacía, rodea esa expresión y al menos un carácter más entre paréntesis:
- Protege todos tus guiones con el carácter de escape (\) siempre que no sean el operador de intervalo o el de exclusión de PowerSearch:
- No uses el operador de final de palabra antes del de final de segmento. Es redundante y esa combinación no funciona en las versiones más antiguas:
- Para buscar repeticiones de asteriscos, usa su código hexadecimal:
- Evita la normalización de caracteres:
<(i?phone)> mejor que <i?phone>Super\-8 mejor que Super-8Atentamente$ mejor que Atentamente>$(\x2A)+ mejor que \*+[:alpha:]+ o [a-záéíóúüñ]+ mejor que [a-z]+Reflexión final
Dado que la versión 2.9 se encuentra congelada desde 2013 y que la 3.0 no deja de evolucionar, es probable que esta brecha ente versiones aumente con el tiempo. Esto sería incluso deseable si se amplía la sintaxis actual para que admita expresiones regulares menos voraces (que puedan ser lazy en vez de greedy), puedan definirse más de nueve variables o incluya aserciones de longitud cero como las construcciones lookahead y lookbehind. Lograr la compatibilidad con versiones anteriores sería más complicado, pero merecería la pena por el mayor nivel de sofisticación que alcanzarían muchas comprobaciones. Es la esperanza, en definitiva, de que esta primera entrada del blog quede obsoleta cuanto antes.
Posdata. Al releer la entrada suena extraño desear que el estreno de un blog quede obsoleto pronto. Borges decía de los periódicos que se escriben deliberadamente para el olvido. Acaso el mismo destino le está deparado a los blogs. También explicaba una suerte de inmortalidad de la inteligencia en la que «cada vez que repetimos un verso de Dante o de Shakespeare, somos, de algún modo, aquel instante en que Shakespeare o Dante crearon ese verso». Ahora no es imposible que el motivo de esta entrada sea revivir el instante en que Borges dijo que «si al final, cuando termina la obra, el autor piensa que hizo lo que se propuso, la obra no vale nada».