
ApSIC Xbench is one of the best quality assurance tools for translators. It ensures consistency, helps to comply with glossaries and other references, and acts as a safety net to minimise all-too-human errors. It also allows you to create your own quality checks, which are most powerful when you use regular expressions and store them in checklists. For instance, you could code your whole style guide for Xbench to inform you of any non-compliance with a single click of a button.
There are two main versions of Xbench: 2.9, which is freeware, and 3.0. You can download both from Xbench’s official site. Its system of floating licenses is incredibly flexible and easy to use, but it is not hard to imagine that some members of the team may end up using the paid version while others may prefer to stick with the freeware. It may also happen that a freelance translator starts using the free version to test its value before upgrading to 3.0. In any case, there is often the doubt of whether resources, especially checklists, can be shared between versions.
Can the same checklist be used in 2.9 and 3.0?
All checklist files can be imported into any other Xbench version. However, some of their quality checks may not work as intended when moving from one version to another. These differences come from three sources:
- Changes in the syntax of regular expressions
- Bug fixing
- New features
Changes in the syntax of regular expressions
The same expression may find different results in different versions:
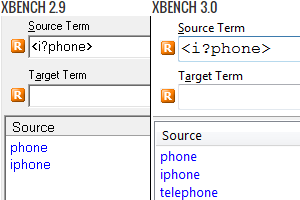
This change was introduced in Xbench 3.0 build 1216. Before this build, the syntax was the same in 2.9 and 3.0. Luckily, the only operators affected are the word and segment anchors:
<: Start of word
>: End of word
^: Start of segment
$: End of segment
Furthermore, the differences only occur when these anchors are followed or preceded by a potentially empty expression. That is, when combined with the following operators:
?: Previous character is optional
*: Zero repetitions or more
That is the situation in the example above. In theory, the expression <i?phone> should only match phone or iphone. However, in version 3.0 it also finds telephone because after the syntax change the start-of-word operator (<) is only taken into account if the i exists. To achieve the results intended, you would need to add grouping via parentheses so that the < anchor ceases to affect a potentially empty expression:
<(i?p)hone>
<(i?ph)one>
<(i?phone)>
Etc.
These parentheses are deemed unnecessary in the most common regular expression flavours, which may be why this change was reverted soon after. However, apparently they stopped halfway through: they only rolled back the change when it involved end-of-segment or end-of-word anchors. The following table reflects this inconsistency and the syntax variation through versions. The cells in green indicate same syntax than in 2.9 and the numbers refer to Xbench 3.0 builds, not the evolution of regular expressions in the Middle Ages:
| Search | 1186 and below | 1216-1243 | 1266 and above |
|---|---|---|---|
| phone or iphone | <i?phone> | <(i?phone)> | <(i?phone)> |
| phone or phones | <phones?> | <(phones?)> | <phones?> |
Bug fixing and new features
Two other sources of differences are bug fixes and new features. Some of the bug fixing may affect the behaviour of certain regular expression operators, so it is wise to keep them in mind when switching to a different Xbench version. For example, in Xbench 3.0 build 1336 and below you need to escape all hyphens so that they are not confused with range operators. In the summary below you will find an example of this case (it is the one involving Wi-Fi) and other similar issues.
As to the implementation of new features, special care must be taken when normalising native characters. For example, with normalisation enabled, searching vídeo would find both video and vídeo, two alternative spellings of the same word in Spanish (the former being the preferred spelling in Latin America, the latter the usual spelling in Spain). A version without this option would only find vídeo. Happily, there are several expressions which would work fine in any version, such as these ones:
v[ií]deo
v(i|í)deo
video|vídeoSumming up
Checklist files (.xbckl) can be loaded into any Xbench build regardless of the version they were created in. However, many checks may lose their efficiency partially or totally if they are not adapted to each version, especially when using regular expressions.
The following tips can improve the compatibility of your regular expressions through different versions:
- If the start-of-word or start-of-segment anchors are followed by a potentially empty expression, enclose that expression and at least one more character within parentheses:
- Escape all hyphens, unless they act as range operators (or exclusions in PowerSearch mode):
- Do not use the end-of-word operator before an end-of-segment anchor. That combination is redundant and does not work properly in older versions:
- To search repetitions of asterisks, use their hexadecimal code:
- Avoid normalisation of native characters (in the example below, [a-záéíóúüñ] represents all letter characters used in Spanish):
<(i?phone)> rather than <i?phone>Wi\-Fi rather than Wi-FiSincerely$ rather than Sincerely>$(\x2A)+ rather than \*+[:alpha:]+ or [a-záéíóúüñ]+ rather than [a-z]+ Final thoughts
Since development of version 2.9 was frozen around 2013 and version 3.0 is constantly improving, it is extremely likely that this gap between versions will get broader and broader. This scenario would even be welcome if the syntax of regular expressions were to support lazy matching, more than nine variables and zero-length assertions such as lookaround constructs. It would make compatibility between versions more challenging, but the sophistication of those new quality checks would make it worthwhile. I guess I am actually expressing the hope that this first entry of the blog becomes obsolete as soon as possible.
Postscript. It now sounds strange to wish for the obsolescence of a blog debut. Borges used to say that newspapers are written intentionally for oblivion. It may well be that the same destiny is in store for blogs. He also surveyed some kind of immortality of the intelligence where “in some way, each time we repeat a verse by Dante or Shakespeare we become that very instant when Dante or Shakespeare created that verse.” At this point, it does not seem impossible that the motive of this entry is to experience the moment when Borges said that “a piece is worthless if, upon finishing it, an auhtor believes he has achieved what he set out to achieve.”